Project 3
Vivi Feathers & Siyuan Su 2023-11-02
Introduction
Diabetes are one of the most prevalent chronic disease that are facing people in the United States as well as in the world. It is estimated that as large as 11.6% of the US population have diabetes, more than 1/3 of the US population have pre-diabetes. Diabetes is a serious disease in which individuals lose the ability to effectively regulate levels of glucose in the blood, and could eventually contribute to complications like heart disease, vision loss, lower-limb amputation and kidney diseases. According to the CDC website (https://www.cdc.gov/diabetes/), At age 50, life expectancy is 6 years shorter for people with type 2 diabetes than for people without it.
Although there are multiple treatment regime for diabetic individual to effectively control their blood sugar level, there is no cure for the disease. To make things worse, about 25% of diabetic individuals were not diagnosed. So there are urgent unmet medical needs to 1. Find effective preventative measurement to prevent individuals from developing diabetes and 2. Predict potential pre-diabetic/diabetic individuals from their life-style related information before they get diagnosed at a hospital. 3. Find effective measures to help individuals with diabetic to live a quality life. Making meaningful insight by exploring data analysis and making prediction using large cohort comprehensive health data set could help provide solution to the needs mentioned above.
The data set we’ll be exploring is from The Behavioral Risk Factor Surveillance System (BRFSS), a health-related telephone survey that is collected annually by the CDC. The response is a binary variable that has 2 classes. 0 is for no diabetes, and 1 is for pre-diabetes or diabetes. There are also 21 variables collected in the data set that might have some association with the response.
In order to learn the distribution of those variables and their relationship with each other, we will conduct a series of data exploratory analysis and generate contingency tables, summary tables, chi-square tests, bar plots, density plots and correlation chart.
After getting some general understanding about the data, we are planning on spitting the data set into training and test set, fitting some prediction models on the training set with different model types and turning parameters, also utilizing the cross-validation method for model selection, and log-loss for model performance evaluation. Our final goal is to find the model that returns the lowest log-loss value when applied on the test set for prediction.
The model types that we will investigate are:
- Logistic regression model.
- LASSO logistic regression model.
- Classification tree model.
- Random forest model.
- Logistic model tree.
- Linear discriminant analysis.
Data
First of all, We will call the required packages and read in the
“diabetes_binary_health_indicators_BRFSS2015.csv” file. According to the
data
dictionary,
there are 22 columns and most of them are categorical variables, we will
convert them to factors and replace the original variables in the code
below using the as.factor function. Additionally, since Education
level one has very a few subjects, we will combine Education level 1 and
2 then replace the original Education variable using a series of
if_else functions. Lastly, we will utilize a filter function and
subset the “diabetes” data set corresponding to the params$Education
value in YAML header for R markdown automation purpose.
library(tidyverse)
library(ggplot2)
library(caret)
library(GGally)
library(devtools)
library(leaps)
library(glmnet)
library(RWeka)
library(gridExtra)
library(readr)
library(scales)
library(MASS)
diabetes <- read_csv(file = "diabetes_binary_health_indicators_BRFSS2015.csv")
# for log-loss purpose, create a new variable and assign value as "YES" for the records have Diabetes_binary = 1 and 'NO' otherwise.
diabetes <- diabetes %>%
mutate(diabetes_dx = as.factor(if_else(Diabetes_binary == 1, "Yes", "No")))
#use `as.factor` function to replace the original variables.
diabetes$Diabetes_binary <- as.factor(diabetes$Diabetes_binary)
diabetes$HighBP <- as.factor(diabetes$HighBP)
diabetes$HighChol <- as.factor(diabetes$HighChol)
diabetes$CholCheck <- as.factor(diabetes$CholCheck)
diabetes$Smoker <- as.factor(diabetes$Smoker)
diabetes$Stroke <- as.factor(diabetes$Stroke)
diabetes$HeartDiseaseorAttack <- as.factor(diabetes$HeartDiseaseorAttack)
diabetes$PhysActivity <- as.factor(diabetes$PhysActivity)
diabetes$Fruits <- as.factor(diabetes$Fruits)
diabetes$Veggies <- as.factor(diabetes$Veggies)
diabetes$HvyAlcoholConsump <- as.factor(diabetes$HvyAlcoholConsump)
diabetes$AnyHealthcare <- as.factor(diabetes$AnyHealthcare)
diabetes$NoDocbcCost <- as.factor(diabetes$NoDocbcCost)
diabetes$GenHlth <- as.factor(diabetes$GenHlth)
diabetes$DiffWalk <- as.factor(diabetes$DiffWalk)
diabetes$Sex <- as.factor(diabetes$Sex)
diabetes$Age <- as.factor(diabetes$Age)
diabetes$Income <- as.factor(diabetes$Income)
# combine level 1 and 2 of education
diabetes$Education <- as.factor(if_else(diabetes$Education == 1, 1,
if_else(diabetes$Education == 2, 1,
if_else(diabetes$Education == 3, 2,
if_else(diabetes$Education == 4, 3,
if_else(diabetes$Education == 5, 4,
if_else(diabetes$Education == 6, 5, NA)))))))
# subset data set based on parameter in YAML header
diabetes_sub <- diabetes %>%
filter(Education == params$Education)
Summarizations
Now we are ready to perform an exploratory data analysis, and give some Summarizations about the center, spread and distribution of numeric variables in the form of tables and plots. Also provide contingency tables and bar plots for categorical variables.
The response: “Diabetes_binary”
Since “Diabetes_binary” is a binary variable, we will create a one way
contingency table with table function to see the count of subjects
with and without diabetes in this education group. Also visualize the
result in a bar chart using ggplot + geom_bar function. For label
specification on x axis, x ticks, y axis and legend, we will use the
scale_x_discrete, the scale_fill_discrete and the labs functions.
table(diabetes_sub$Diabetes_binary)
##
## 0 1
## 59556 10354
g <- ggplot(data = diabetes_sub, aes(x = Diabetes_binary, fill = Diabetes_binary))
g + geom_bar(alpha = 0.6) +
scale_x_discrete(breaks=c("0","1"),
labels=c("No", "Yes")) +
scale_fill_discrete(name = "Diabetes Diagnosis", labels = c("No", "Yes")) +
labs(x = "Diabetes Diagnosis", y = "Subject count", title = "Bar plot of subject with diabetes and subject withou diabetes count")
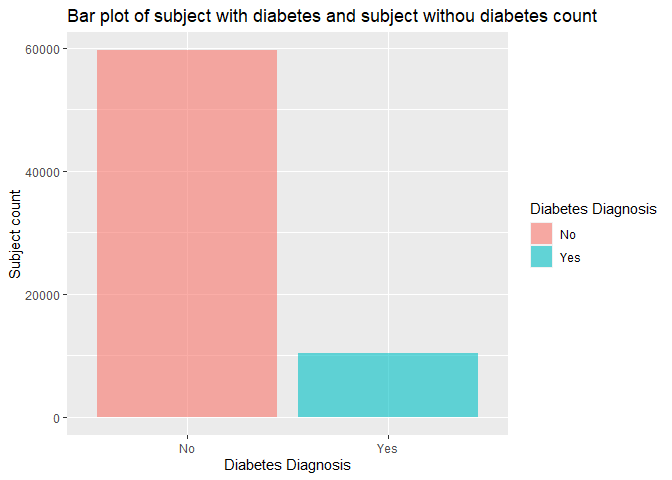
From this bar chart, we can see which diagnosis group has more subjects in this education level.
Contigency table and Chi-square
Now we want to investigate the relationship between having diabetes vs all the categorical variables. we will create a function which generates a contingency table, calculates the row percentage for each level of the corresponding categorical variable in both diagnosis groups, and gives the chi-square result based on the contingency table.
chisq <- function (x) {
#generate contingency table
a <- table(diabetes_sub$Diabetes_binary, x)
#calculate the row percentage and combine with original data set
c <- cbind(a, a/rowSums(a))
#run chi-square test
b <- chisq.test(a, correct=FALSE)
return(list(a, c, b))
}
chisq(diabetes_sub$HighBP)
## [[1]]
## x
## 0 1
## 0 36499 23057
## 1 2520 7834
##
## [[2]]
## 0 1 0 1
## 0 36499 23057 0.6128518 0.3871482
## 1 2520 7834 0.2433842 0.7566158
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 4882.2, df = 1, p-value < 2.2e-16
chisq(diabetes_sub$HighChol)
## [[1]]
## x
## 0 1
## 0 36855 22701
## 1 3368 6986
##
## [[2]]
## 0 1 0 1
## 0 36855 22701 0.6188293 0.3811707
## 1 3368 6986 0.3252849 0.6747151
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 3110.9, df = 1, p-value < 2.2e-16
chisq(diabetes_sub$CholCheck)
## [[1]]
## x
## 0 1
## 0 2766 56790
## 1 79 10275
##
## [[2]]
## 0 1 0 1
## 0 2766 56790 0.046443683 0.9535563
## 1 79 10275 0.007629901 0.9923701
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 340.38, df = 1, p-value < 2.2e-16
chisq(diabetes_sub$Smoker)
## [[1]]
## x
## 0 1
## 0 30826 28730
## 1 4716 5638
##
## [[2]]
## 0 1 0 1
## 0 30826 28730 0.5175969 0.4824031
## 1 4716 5638 0.4554761 0.5445239
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 136.19, df = 1, p-value < 2.2e-16
chisq(diabetes_sub$Stroke)
## [[1]]
## x
## 0 1
## 0 57561 1995
## 1 9366 988
##
## [[2]]
## 0 1 0 1
## 0 57561 1995 0.9665021 0.03349788
## 1 9366 988 0.9045779 0.09542206
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 828.02, df = 1, p-value < 2.2e-16
chisq(diabetes_sub$HeartDiseaseorAttack)
## [[1]]
## x
## 0 1
## 0 55001 4555
## 1 7991 2363
##
## [[2]]
## 0 1 0 1
## 0 55001 4555 0.9235174 0.07648264
## 1 7991 2363 0.7717790 0.22822098
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 2277.7, df = 1, p-value < 2.2e-16
chisq(diabetes_sub$PhysActivity)
## [[1]]
## x
## 0 1
## 0 14261 45295
## 1 3766 6588
##
## [[2]]
## 0 1 0 1
## 0 14261 45295 0.2394553 0.7605447
## 1 3766 6588 0.3637242 0.6362758
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 711.79, df = 1, p-value < 2.2e-16
chisq(diabetes_sub$Fruits)
## [[1]]
## x
## 0 1
## 0 22335 37221
## 1 4268 6086
##
## [[2]]
## 0 1 0 1
## 0 22335 37221 0.3750252 0.6249748
## 1 4268 6086 0.4122078 0.5877922
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 51.733, df = 1, p-value = 6.359e-13
chisq(diabetes_sub$Veggies)
## [[1]]
## x
## 0 1
## 0 10817 48739
## 1 2319 8035
##
## [[2]]
## 0 1 0 1
## 0 10817 48739 0.1816274 0.8183726
## 1 2319 8035 0.2239714 0.7760286
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 103.64, df = 1, p-value < 2.2e-16
chisq(diabetes_sub$HvyAlcoholConsump)
## [[1]]
## x
## 0 1
## 0 55846 3710
## 1 10096 258
##
## [[2]]
## 0 1 0 1
## 0 55846 3710 0.9377057 0.06229431
## 1 10096 258 0.9750821 0.02491791
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 230.16, df = 1, p-value < 2.2e-16
chisq(diabetes_sub$AnyHealthcare)
## [[1]]
## x
## 0 1
## 0 3372 56184
## 1 388 9966
##
## [[2]]
## 0 1 0 1
## 0 3372 56184 0.05661898 0.9433810
## 1 388 9966 0.03747344 0.9625266
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 63.532, df = 1, p-value = 1.578e-15
chisq(diabetes_sub$NoDocbcCost)
## [[1]]
## x
## 0 1
## 0 53790 5766
## 1 9173 1181
##
## [[2]]
## 0 1 0 1
## 0 53790 5766 0.9031836 0.09681644
## 1 9173 1181 0.8859378 0.11406220
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 29.313, df = 1, p-value = 6.159e-08
chisq(diabetes_sub$GenHlth)
## [[1]]
## x
## 1 2 3 4 5
## 0 10290 22605 18136 6282 2243
## 1 314 1869 4070 2817 1284
##
## [[2]]
## 1 2 3 4 5 1 2 3 4 5
## 0 10290 22605 18136 6282 2243 0.17277856 0.3795587 0.3045201 0.1054806 0.03766203
## 1 314 1869 4070 2817 1284 0.03032644 0.1805099 0.3930848 0.2720688 0.12401004
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 5580.4, df = 4, p-value < 2.2e-16
chisq(diabetes_sub$DiffWalk)
## [[1]]
## x
## 0 1
## 0 50507 9049
## 1 6401 3953
##
## [[2]]
## 0 1 0 1
## 0 50507 9049 0.8480590 0.1519410
## 1 6401 3953 0.6182152 0.3817848
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 3077.9, df = 1, p-value < 2.2e-16
chisq(diabetes_sub$Sex)
## [[1]]
## x
## 0 1
## 0 35539 24017
## 1 5683 4671
##
## [[2]]
## 0 1 0 1
## 0 35539 24017 0.5967325 0.4032675
## 1 5683 4671 0.5488700 0.4511300
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 83.509, df = 1, p-value < 2.2e-16
chisq(diabetes_sub$Income)
## [[1]]
## x
## 1 2 3 4 5 6 7 8
## 0 1923 2517 3713 5085 7095 10239 11514 17470
## 1 514 798 951 1225 1484 1757 1734 1891
##
## [[2]]
## 1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8
## 0 1923 2517 3713 5085 7095 10239 11514 17470 0.03228894 0.04226274 0.06234468 0.08538183 0.1191316 0.1719222 0.1933306 0.2933374
## 1 514 798 951 1225 1484 1757 1734 1891 0.04964265 0.07707166 0.09184856 0.11831176 0.1433263 0.1696929 0.1674715 0.1826347
##
## [[3]]
##
## Pearson's Chi-squared test
##
## data: a
## X-squared = 986.43, df = 7, p-value < 2.2e-16
We need to pay attention to the categorical variable with a significant chi-square result (p value smaller than 0.05), that means this categorical variable may have certain relationship with the diabetes diagnosis.
“HighBP”
As we all know, high blood pressure and diabetes are related, we want to
create a bar chart and visualize the high blood pressure subjects’ count
and ratio in each diagnosis group. Here we will again, use the gglot
function and the geom_bar function to create the plot. Like last bar
chart, we also will set labels for x axis, x ticks, y axis and legend
with the scale_x_discrete, the scale_fill_discrete and thelabs
functions.
# create a bar plot using the gglot and the geom_bar function.
h <- ggplot(data = diabetes_sub, aes(x = Diabetes_binary, fill = HighBP))
h + geom_bar(position = "dodge", alpha = 0.6) +
scale_x_discrete(breaks=c("0","1"),
labels=c("No", "Yes")) +
scale_fill_discrete(name = "High Blood Pressure", labels = c("No", "Yes")) +
labs(x = "Diabetes Diagnosis", y = "Subject count", title = "Bar plot of high blood pressure subject count in diabetes and non-diabetes group")
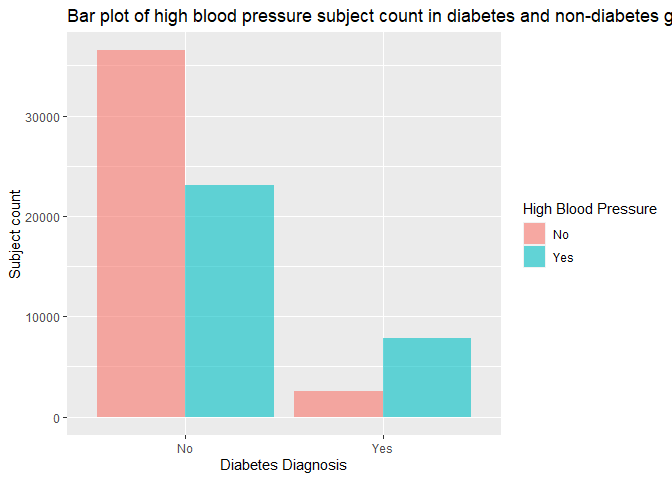
In the bar chart above, we need to focus on the count and ratio of subjects with high blood pressure vs subjects without in both diabetes and non-diabetes group, and verify if the ratio of high blood pressure subjects in the diabetes group is higher than the non-diabetes group’s as we assumed.
“HighChol”
Another health condition that associates with diabetes is high cholesterol, we also want to create a bar chart and compare the high cholesterol subjects’ count and ratio in each diagnosis group, using all the functions we used for previous bar plots.
# create a bar plot using the gglot and the geom_bar function.
h <- ggplot(data = diabetes_sub, aes(x = Diabetes_binary, fill = HighChol))
h + geom_bar(position = "dodge", alpha = 0.6) +
scale_x_discrete(breaks=c("0","1"),
labels=c("No", "Yes")) +
scale_fill_discrete(name = "High Cholesterol", labels = c("No", "Yes")) +
labs(x = "Diabetes Diagnosis", y = "Subject count", title = "Bar plot of high cholesterol subject count in diabetes and non-diabetes group")
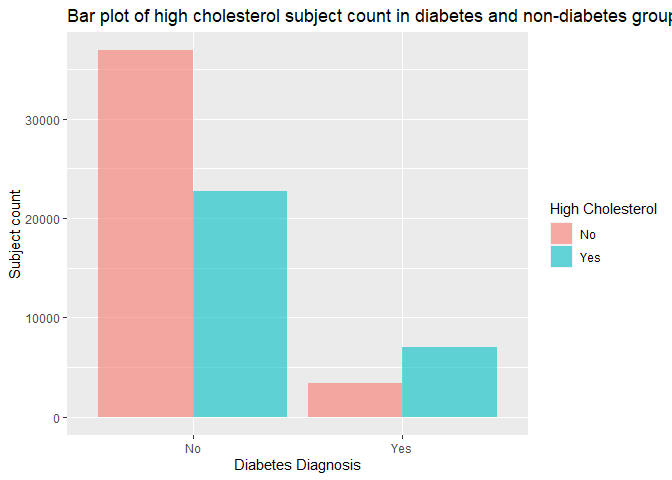
In the bar chart above, we also need to look at the count and ratio of subjects with high cholesterol vs subjects without in both diabetes and non-diabetes group, and verify if the ratio of high cholesterol subjects in the diabetes group is higher than the non-diabetes group’s as we expected.
“BMI”
The association of high BMI and diabetes are proved in many scientific
studies, in order to verify if this association also exists in our data,
we are looking into the distribution of BMI in both diagnosis group by
creating a summary table using group_by and summarise function, as
well as generating a kernel density plot with ggplot and
geom_density function. Additionally, we want to conduct a two sample
t-test with t.test function and investigate if the means in each
diagnosis group are different from each other.
#create a summary table for BMI to display the center and spread
diabetes_sub %>%
group_by(Diabetes_binary) %>%
summarise(Mean = mean(BMI), Standard_Deviation = sd(BMI),
Variance = var(BMI), Median = median(BMI),
q1 = quantile(BMI, probs = 0.25),
q3 = quantile(BMI, probs = 0.75))
## # A tibble: 2 × 7
## Diabetes_binary Mean Standard_Deviation Variance Median q1 q3
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0 28.3 6.45 41.5 27 24 31
## 2 1 32.4 7.44 55.4 31 27 36
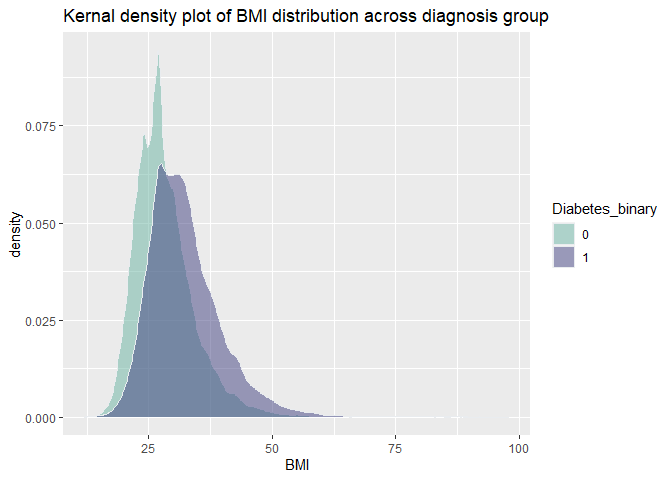
#generate a kernal density plot to show the distribution of BMI
i <- ggplot(data = diabetes_sub, aes(x = BMI, fill = Diabetes_binary))
i + geom_density(adjust = 1, color="#e9ecef", alpha=0.5, position = 'dodge') +
scale_fill_manual(values=c("#69b3a2", "#404080")) +
labs(x = "BMI", title = "Kernal density plot of BMI distribution across diagnosis group")
#conduct a two sample t test for BMI in both diagnosis groups
t.test(BMI ~ Diabetes_binary, data = diabetes_sub, alternative = "two.sided", var.equal = FALSE)
##
## Welch Two Sample t-test
##
## data: BMI by Diabetes_binary
## t = -52.443, df = 13190, p-value < 2.2e-16
## alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0
## 95 percent confidence interval:
## -4.230668 -3.925805
## sample estimates:
## mean in group 0 mean in group 1
## 28.27399 32.35223
The summary table gives us the center (mean and median) and spread (standard_deviation, variance, q1 and q3) of BMI in each diagnosis group. The density plot shows the distribution of BMI in each diagnosis group, we can estimate the means and standard deviations, also visualize their differences. Lastly, the two sample t-test returns the 95% confidence interval of mean difference, and the t statistic, degree of freedom and p-value as t-test result, we need to see if the p-value is smaller than 0.05 to decide whether we will reject the null hypothesis (true difference in means between two diagnosis is equal to 0).
Grid of bar and density plots
Beside above 3 variables that we investigated individually, we still want to have a brief concept about the distribution of other variables that were not mentioned that often in scientific articles about their association with diabetes diagnosis. Compared with contingency tables, bar/density plots are often visually more appealing and easier to understand.
In order to create bar plot for visualizing the distribution of diabetic
people in each category of variables, we need to use the ggplot
package, and the geom_bar function will be applied. For numeric
variable, the geom_density function will be used for displaying their
distributions. As previous, Function labs were used to input the label
for each plot, and scale_x_discrete function was used to create label
for each category on the x-axis, meanwhile scale_fill_discrete
function was used to provide label in the legend.
PHlthplot<-ggplot(diabetes_sub,aes(x=PhysHlth,fill=Diabetes_binary))+
geom_density(adjust=1,alpha=0.5)+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))+
labs(x="Number of days physical health not good")
MHlthplot<-ggplot(diabetes_sub,aes(x=MentHlth,fill=Diabetes_binary))+
geom_density(adjust=1,alpha=0.5)+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))+
labs(x="Number of days mental health not good")
Physplot<-ggplot(diabetes_sub,aes(x=PhysActivity))+
geom_bar(aes(fill=(Diabetes_binary)))+
labs(x="Physically Active?")+
scale_x_discrete(labels=c("No","Yes"))+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))
Fruitplot<-ggplot(diabetes_sub,aes(x=Fruits))+
geom_bar(aes(fill=(Diabetes_binary)))+
labs(x="Fruit lover?")+
scale_x_discrete(labels=c("No","Yes"))+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))
Veggieplot<-ggplot(diabetes_sub,aes(x=Veggies))+
geom_bar(aes(fill=(Diabetes_binary)))+
labs(x="Veggies eater?")+
scale_x_discrete(labels=c("No","Yes"))+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))
GHlthplot<-ggplot(diabetes_sub,aes(x=GenHlth))+
geom_bar(aes(fill=(Diabetes_binary)))+
labs(x="General Health Condition")+
scale_x_discrete(labels=c("E","VG", "G", "F", "P"))+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))
Incomeplot<-ggplot(diabetes_sub,aes(x=Income))+
geom_bar(aes(fill=(Diabetes_binary)))+
labs(x="Annual Household Income level")+
scale_x_discrete(labels=c("1","2", "3","4", "5","6","7", "8"))+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))
Alcoholplot<-ggplot(diabetes_sub,aes(x=HvyAlcoholConsump))+
geom_bar(aes(fill=(Diabetes_binary)))+
labs(x="Heavy Drinker?")+
scale_x_discrete(labels=c("No","Yes"))+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))
It would be very cumbersome to view each graph independently, so we are
putting them in a tile with the grid.arrange function.
grid.arrange(Physplot,Fruitplot,Veggieplot,GHlthplot,Alcoholplot,Incomeplot,PHlthplot,MHlthplot,ncol=3)
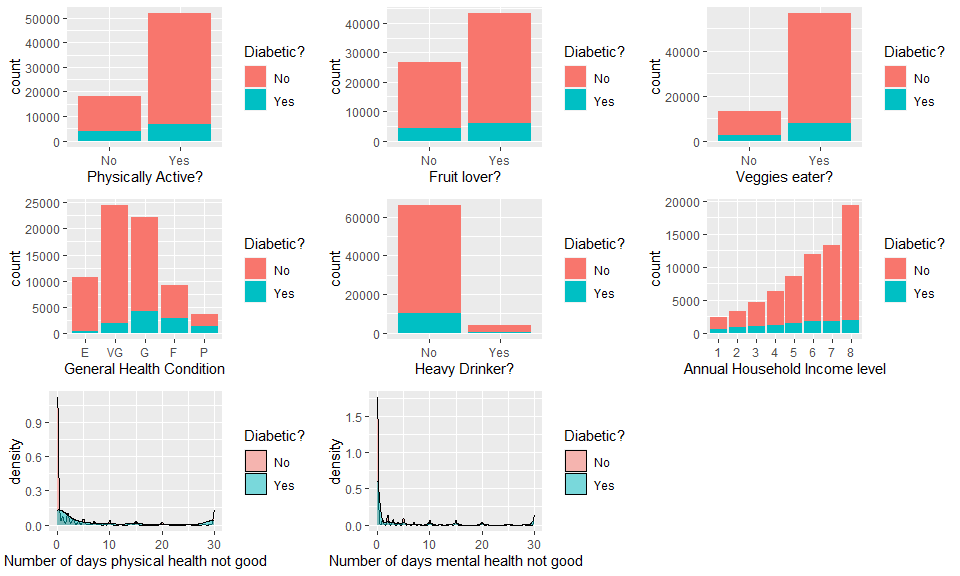
The contrasting color red (no diabetes) and blue (have diabetes) provides a straightforward way to visualize the how the ratio of people who have diabetes are affected by the value of variables. Note that different variables may have interactions, if interested we could further split the value of a variable by another variable, just like what will be shown in the next graph.
diabetes_Edu1_nofruit<-diabetes_sub%>%filter(Fruits=="0")
diabetes_Edu1_yesfruit<-diabetes_sub%>%filter(Fruits=="1")
diabetes_Edu1_noveggie<-diabetes_sub%>%filter(Veggies=="0")
diabetes_Edu1_yesveggie<-diabetes_sub%>%filter(Veggies=="1")
Physnofruitplot<-ggplot(diabetes_Edu1_nofruit,aes(x=PhysActivity))+
geom_bar(aes(fill=(Diabetes_binary)))+
ggtitle("Fruit hater")+
labs(x="Physically Active?")+
scale_x_discrete(labels=c("No","Yes"))+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))
Physyesfruitplot<-ggplot(diabetes_Edu1_yesfruit,aes(x=PhysActivity))+
geom_bar(aes(fill=(Diabetes_binary)))+
ggtitle("Fruit lover")+
labs(x="Physically Active?")+
scale_x_discrete(labels=c("No","Yes"))+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))
Physnoveggieplot<-ggplot(diabetes_Edu1_noveggie,aes(x=PhysActivity))+
geom_bar(aes(fill=(Diabetes_binary)))+
ggtitle("Veggie hater")+
labs(x="Physically Active?")+
scale_x_discrete(labels=c("No","Yes"))+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))
Physyesveggieplot<-ggplot(diabetes_Edu1_yesveggie,aes(x=PhysActivity))+
geom_bar(aes(fill=(Diabetes_binary)))+
ggtitle("Veggie lover")+
labs(x="Physically Active?")+
scale_x_discrete(labels=c("No","Yes"))+
scale_fill_discrete(name="Diabetic?", label=c("No","Yes"))
grid.arrange(Physnofruitplot,Physyesfruitplot,Physnoveggieplot,Physyesveggieplot)
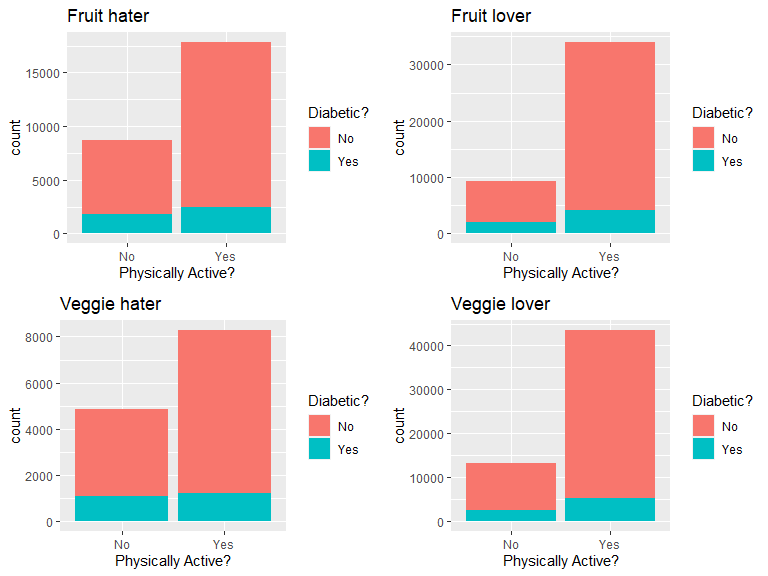
This plot panel showed the effect of physical activity on diabetes status in people who eat/do not eat fruits or veggies. Compared with diabetes patients, is there higher ratio of physically active people in the non-diabetes group that are also fruit & vegetable lovers?
Correlation among numeric variables
Before fitting any model, we also want to test the correlation among
numeric variables, in case there is collinearity that diminishes our
ability to determine which variables are responsible for change in the
response variable. For this reason, we should determine correlations
between all variables and consider removing ones that are problematic.
We can do this by creating a correlation plot with ggpairs() from the
GGally package.
x <- diabetes_sub[, c(5, 16, 17)]
GGally::ggpairs(x)
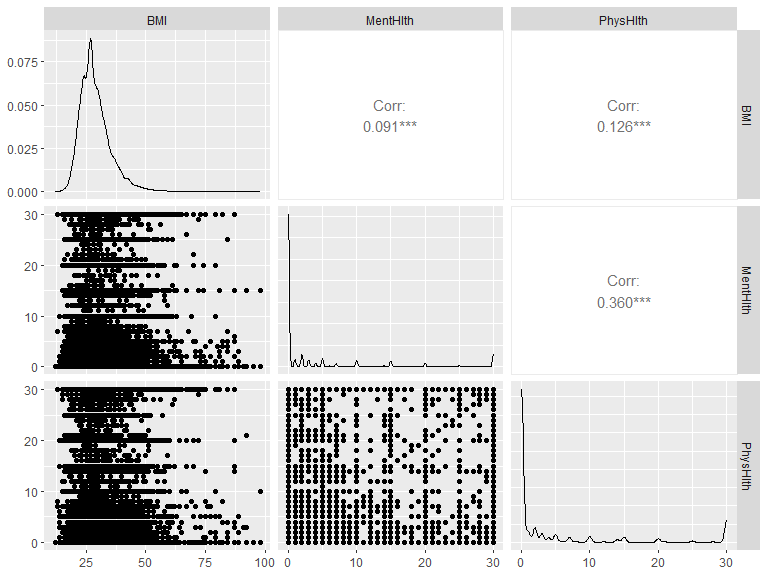
Let’s look for the pairs that have correlation coefficient higher than 0.4. If we do find such pairs, we need to refer to the correlations between each variable and the response & other predictors, as well as some background knowledge (may do a literature review), in order to decide which variable will be include into the models.
Modeling
Since we gained some basic understanding of the data, we can now fit different models and select the best one for prediction.
Training and test set
The first step is to split our data to a training and test set. We will
use the createDataPartition function and split the data by 70% as the
training set and 30% as the test set.
set.seed(20)
index <- createDataPartition(diabetes_sub$Diabetes_binary, p = 0.70, list = FALSE)
train <- diabetes_sub[index, ]
test <- diabetes_sub[-index, ]
Log-Loss
All of our models’ performance will be evaluated by Log-loss. Log loss, also known as logarithmic loss, indicates how close a prediction probability comes to the corresponding true binary value. Thus, it is a common evaluation metric for binary classification models. There are three steps to calculate Log Loss:
- Finding the corrected probabilities.
- Taking a log of corrected probabilities.
- Taking the negative average of the values from step 2.
And the formula is as below:

From the formula we can tell, the lower log-loss is, the better the model performs.
The reason that log-loss is preferred to accuracy is: For accuracy, model returns 1 if predicted probability is > .5 otherwise 0. We could get some prediction probabilities very close to 0.5, but are converted to 1 and 0 which actually match with the true results. Such model could have 100% accuracy but their prediction probabilities are at board line of being wrong. If we use accuracy for model selection, we will keep a bad model. On the other hand, log-loss calculate how far away the prediction probabilities are from the true values, and the log-loss of such model will be high, which reveal the model’s true performance. Thus, log-loss is more reliable and accurate for model selection.
Logistic regression
The first model we are fitting is logistic regression, which is a generalized linear model that models the probability of an event by calculating the log-odds for the event based on the linear combination of one or more independent variables. The most common logistic regression has a single binary variable as the response, usually the two values are coded as “0” and “1”.
In logistic regression, the dependent variable is a logit, which is the natural log of the odds and assumed to be linearly related to X as the formula below:

In our data set, logistic regression models are more suitable for our binary response than linear regression models because:
- If we use linear regression, the predicted values will become greater than one and less than zero if we move far enough on the X-axis. Such values are not realistic for binary variable.
- One of the assumptions of regression is that the variance of Y is constant across values of X (homoscedasticity). This can not be the case with a binary variable.
- The significance testing of the b weights rest upon the assumption that errors of prediction (Y-Y’) are normally distributed. Because Y only takes the values 0 and 1, this assumption is pretty hard to justify.
Now, let’s fit 3 logistic regression models with the train function on
the training data set, and use cross-validation with 5 folds for model
selection. After the best model is picked, use the predict function to
apply it on the test data set and merge the predicted results with the
test set’s true response. We will use the mnLogLoss function to
evaluate their performance with a log-loss method.
After log-loss values get calculated for all three models, we will
create a data frame with all the log-loss values and their corresponding
model names, then return the row with the lowest log-loss value by using
the which.min function. Lastly, we will insert the model name as an
inline R code into the conclusion.
Model one
We will include all the low level variables in our first model:
#fit the model on the training data set
full_log <- train(diabetes_dx ~ HighBP + HighChol + CholCheck + BMI + Smoker + Stroke + HeartDiseaseorAttack
+ PhysActivity + Fruits + Veggies + HvyAlcoholConsump + AnyHealthcare + NoDocbcCost + GenHlth + MentHlth
+ PhysHlth + DiffWalk + Sex + Age + Income,
data=train,
method = "glm",
family = "binomial",
metric="logLoss",
preProcess = c("center", "scale"),
trControl = trainControl(method = "cv", number = 5, classProbs=TRUE, summaryFunction=mnLogLoss))
full_log
## Generalized Linear Model
##
## 48938 samples
## 20 predictor
## 2 classes: 'No', 'Yes'
##
## Pre-processing: centered (40), scaled (40)
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 39151, 39151, 39150, 39150, 39150
## Resampling results:
##
## logLoss
## 0.3331174
summary(full_log)
##
## Call:
## NULL
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.3851068 0.0219735 -108.545 < 2e-16 ***
## HighBP1 0.3604637 0.0162663 22.160 < 2e-16 ***
## HighChol1 0.2866876 0.0149519 19.174 < 2e-16 ***
## CholCheck1 0.2136093 0.0274780 7.774 7.61e-15 ***
## BMI 0.4007302 0.0137780 29.085 < 2e-16 ***
## Smoker1 -0.0231357 0.0146155 -1.583 0.113431
## Stroke1 0.0428394 0.0111062 3.857 0.000115 ***
## HeartDiseaseorAttack1 0.0813427 0.0117154 6.943 3.83e-12 ***
## PhysActivity1 -0.0204661 0.0138298 -1.480 0.138912
## Fruits1 -0.0001507 0.0147368 -0.010 0.991840
## Veggies1 -0.0214010 0.0140169 -1.527 0.126812
## HvyAlcoholConsump1 -0.1618696 0.0190728 -8.487 < 2e-16 ***
## AnyHealthcare1 0.0102542 0.0169105 0.606 0.544263
## NoDocbcCost1 0.0007340 0.0147111 0.050 0.960206
## GenHlth2 0.3113245 0.0364888 8.532 < 2e-16 ***
## GenHlth3 0.6260560 0.0346848 18.050 < 2e-16 ***
## GenHlth4 0.6154164 0.0272931 22.548 < 2e-16 ***
## GenHlth5 0.4314830 0.0210112 20.536 < 2e-16 ***
## MentHlth -0.0009506 0.0144621 -0.066 0.947592
## PhysHlth -0.0764609 0.0163174 -4.686 2.79e-06 ***
## DiffWalk1 0.0606004 0.0144696 4.188 2.81e-05 ***
## Sex1 0.1241842 0.0147006 8.448 < 2e-16 ***
## Age2 0.0812107 0.0564549 1.439 0.150290
## Age3 0.1654860 0.0595567 2.779 0.005459 **
## Age4 0.3061613 0.0621982 4.922 8.55e-07 ***
## Age5 0.3637510 0.0655025 5.553 2.80e-08 ***
## Age6 0.4291560 0.0703240 6.103 1.04e-09 ***
## Age7 0.5988161 0.0819971 7.303 2.82e-13 ***
## Age8 0.6568857 0.0880870 7.457 8.84e-14 ***
## Age9 0.7704925 0.0910880 8.459 < 2e-16 ***
## Age10 0.7891851 0.0887985 8.887 < 2e-16 ***
## Age11 0.6839615 0.0752875 9.085 < 2e-16 ***
## Age12 0.5680141 0.0640078 8.874 < 2e-16 ***
## Age13 0.5152847 0.0648348 7.948 1.90e-15 ***
## Income2 -0.0099698 0.0182760 -0.546 0.585399
## Income3 -0.0185198 0.0206434 -0.897 0.369649
## Income4 -0.0249003 0.0230047 -1.082 0.279073
## Income5 -0.0528074 0.0256717 -2.057 0.039683 *
## Income6 -0.0925998 0.0290859 -3.184 0.001454 **
## Income7 -0.0868557 0.0302300 -2.873 0.004064 **
## Income8 -0.1466763 0.0345886 -4.241 2.23e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 41050 on 48937 degrees of freedom
## Residual deviance: 32506 on 48897 degrees of freedom
## AIC: 32588
##
## Number of Fisher Scoring iterations: 7
#apply the best model on the test set and merge the predicted results with the true response into one data frame
predicted <- data.frame(obs=test$diabetes_dx,
pred=predict(full_log, test),
predict(full_log, test, type="prob"))
#calculate the log-loss
a <- mnLogLoss(predicted, lev = levels(predicted$obs))
Model two
We will include all the low level variables and interactions between HighBP & HighChol, HighBP & BMI, HighChol & BMI, PhysActivity & BMI, and BMI & GenHlth in our second model:
#fit the model on the training data set
inter_log <- train(diabetes_dx ~ HighBP + HighChol + CholCheck + BMI + Smoker + Stroke + HeartDiseaseorAttack
+ PhysActivity + Fruits + Veggies + HvyAlcoholConsump + AnyHealthcare + NoDocbcCost + GenHlth + MentHlth
+ PhysHlth + DiffWalk + Sex + Age + Income + HighBP:HighChol + HighBP:BMI + HighChol:BMI + PhysActivity:BMI + BMI:GenHlth,
data=train,
method = "glm",
family = "binomial",
metric="logLoss",
preProcess = c("center", "scale"),
trControl = trainControl(method = "cv", number = 5, classProbs=TRUE, summaryFunction=mnLogLoss))
inter_log
## Generalized Linear Model
##
## 48938 samples
## 20 predictor
## 2 classes: 'No', 'Yes'
##
## Pre-processing: centered (48), scaled (48)
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 39150, 39151, 39151, 39150, 39150
## Resampling results:
##
## logLoss
## 0.3329707
summary(inter_log)
##
## Call:
## NULL
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.3882606 0.0226267 -105.551 < 2e-16 ***
## HighBP1 0.4995974 0.0690263 7.238 4.56e-13 ***
## HighChol1 0.0482021 0.0638703 0.755 0.450437
## CholCheck1 0.2136323 0.0274998 7.768 7.94e-15 ***
## BMI 0.3798472 0.0637452 5.959 2.54e-09 ***
## Smoker1 -0.0233822 0.0146236 -1.599 0.109835
## Stroke1 0.0429507 0.0111110 3.866 0.000111 ***
## HeartDiseaseorAttack1 0.0823031 0.0117310 7.016 2.29e-12 ***
## PhysActivity1 -0.0502667 0.0578460 -0.869 0.384862
## Fruits1 -0.0001327 0.0147421 -0.009 0.992817
## Veggies1 -0.0210641 0.0140244 -1.502 0.133108
## HvyAlcoholConsump1 -0.1619904 0.0190770 -8.491 < 2e-16 ***
## AnyHealthcare1 0.0106167 0.0169428 0.627 0.530909
## NoDocbcCost1 0.0007653 0.0147335 0.052 0.958575
## GenHlth2 0.3059523 0.1398515 2.188 0.028692 *
## GenHlth3 0.6729853 0.1301144 5.172 2.31e-07 ***
## GenHlth4 0.6878736 0.0985084 6.983 2.89e-12 ***
## GenHlth5 0.4267823 0.0709734 6.013 1.82e-09 ***
## MentHlth -0.0012073 0.0144841 -0.083 0.933571
## PhysHlth -0.0759661 0.0163141 -4.656 3.22e-06 ***
## DiffWalk1 0.0596264 0.0144809 4.118 3.83e-05 ***
## Sex1 0.1235553 0.0147141 8.397 < 2e-16 ***
## Age2 0.0807493 0.0564599 1.430 0.152658
## Age3 0.1654897 0.0595241 2.780 0.005432 **
## Age4 0.3036282 0.0621964 4.882 1.05e-06 ***
## Age5 0.3602408 0.0655113 5.499 3.82e-08 ***
## Age6 0.4236154 0.0703428 6.022 1.72e-09 ***
## Age7 0.5928285 0.0820197 7.228 4.91e-13 ***
## Age8 0.6500278 0.0881115 7.377 1.61e-13 ***
## Age9 0.7643677 0.0911080 8.390 < 2e-16 ***
## Age10 0.7832677 0.0888131 8.819 < 2e-16 ***
## Age11 0.6790963 0.0752951 9.019 < 2e-16 ***
## Age12 0.5640111 0.0640160 8.810 < 2e-16 ***
## Age13 0.5118807 0.0648357 7.895 2.90e-15 ***
## Income2 -0.0087924 0.0182976 -0.481 0.630856
## Income3 -0.0179276 0.0206650 -0.868 0.385648
## Income4 -0.0243661 0.0230334 -1.058 0.290120
## Income5 -0.0520878 0.0257080 -2.026 0.042751 *
## Income6 -0.0917945 0.0291299 -3.151 0.001626 **
## Income7 -0.0857535 0.0302779 -2.832 0.004623 **
## Income8 -0.1459532 0.0346424 -4.213 2.52e-05 ***
## `HighBP1:HighChol1` -0.0568404 0.0279906 -2.031 0.042286 *
## `HighBP1:BMI` -0.1074830 0.0666402 -1.613 0.106769
## `HighChol1:BMI` 0.2788932 0.0598103 4.663 3.12e-06 ***
## `BMI:PhysActivity1` 0.0298917 0.0552838 0.541 0.588718
## `BMI:GenHlth2` 0.0016889 0.1345297 0.013 0.989984
## `BMI:GenHlth3` -0.0529446 0.1333231 -0.397 0.691283
## `BMI:GenHlth4` -0.0793582 0.1042925 -0.761 0.446705
## `BMI:GenHlth5` 0.0013875 0.0741276 0.019 0.985067
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 41050 on 48937 degrees of freedom
## Residual deviance: 32479 on 48889 degrees of freedom
## AIC: 32577
##
## Number of Fisher Scoring iterations: 7
#apply the best model on the test set and merge the predicted results with the true response into one data frame
predicted2 <- data.frame(obs=test$diabetes_dx,
pred=predict(inter_log, test),
predict(inter_log, test, type="prob"))
#calculate the log-loss
b <- mnLogLoss(predicted2, lev = levels(predicted2$obs))
Model three
We will include all the low level variables and polynomial term for numeric variables in our third model:
#fit the model on the training data set
poly_log <- train(diabetes_dx ~ HighBP + HighChol + CholCheck + I(BMI^2) + BMI + Smoker
+ Stroke + HeartDiseaseorAttack + PhysActivity + Fruits + Veggies + HvyAlcoholConsump + AnyHealthcare + NoDocbcCost + GenHlth
+ I(MentHlth^2) + MentHlth + I(PhysHlth^2) + PhysHlth + DiffWalk + Sex + Age + Income,
data=train,
method = "glm",
family = "binomial",
metric="logLoss",
preProcess = c("center", "scale"),
trControl = trainControl(method = "cv", number = 5, classProbs=TRUE, summaryFunction=mnLogLoss))
poly_log
## Generalized Linear Model
##
## 48938 samples
## 20 predictor
## 2 classes: 'No', 'Yes'
##
## Pre-processing: centered (43), scaled (43)
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 39151, 39150, 39150, 39151, 39150
## Resampling results:
##
## logLoss
## 0.330182
summary(poly_log)
##
## Call:
## NULL
##
## Coefficients:
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.416653 0.022246 -108.635 < 2e-16 ***
## HighBP1 0.340029 0.016337 20.813 < 2e-16 ***
## HighChol1 0.280169 0.014997 18.682 < 2e-16 ***
## CholCheck1 0.210387 0.027467 7.660 1.86e-14 ***
## `I(BMI^2)` -0.896287 0.061348 -14.610 < 2e-16 ***
## BMI 1.337241 0.064107 20.860 < 2e-16 ***
## Smoker1 -0.017779 0.014667 -1.212 0.225440
## Stroke1 0.047142 0.011188 4.214 2.51e-05 ***
## HeartDiseaseorAttack1 0.081231 0.011805 6.881 5.94e-12 ***
## PhysActivity1 -0.013054 0.013887 -0.940 0.347209
## Fruits1 0.001520 0.014786 0.103 0.918106
## Veggies1 -0.023734 0.014066 -1.687 0.091542 .
## HvyAlcoholConsump1 -0.157495 0.019138 -8.230 < 2e-16 ***
## AnyHealthcare1 0.010592 0.016950 0.625 0.532020
## NoDocbcCost1 0.003040 0.014759 0.206 0.836804
## GenHlth2 0.286483 0.036445 7.861 3.82e-15 ***
## GenHlth3 0.596685 0.034708 17.192 < 2e-16 ***
## GenHlth4 0.601264 0.027443 21.910 < 2e-16 ***
## GenHlth5 0.425946 0.021033 20.252 < 2e-16 ***
## `I(MentHlth^2)` 0.099086 0.051312 1.931 0.053475 .
## MentHlth -0.099816 0.053627 -1.861 0.062699 .
## `I(PhysHlth^2)` 0.017214 0.054991 0.313 0.754252
## PhysHlth -0.090688 0.058580 -1.548 0.121596
## DiffWalk1 0.051549 0.014606 3.529 0.000417 ***
## Sex1 0.113036 0.014845 7.614 2.65e-14 ***
## Age2 0.070840 0.056251 1.259 0.207903
## Age3 0.156474 0.059386 2.635 0.008417 **
## Age4 0.284548 0.062097 4.582 4.60e-06 ***
## Age5 0.342180 0.065400 5.232 1.68e-07 ***
## Age6 0.409210 0.070204 5.829 5.58e-09 ***
## Age7 0.573015 0.081884 6.998 2.60e-12 ***
## Age8 0.631848 0.087962 7.183 6.81e-13 ***
## Age9 0.746762 0.090963 8.209 2.22e-16 ***
## Age10 0.767394 0.088676 8.654 < 2e-16 ***
## Age11 0.667511 0.075201 8.876 < 2e-16 ***
## Age12 0.560105 0.063936 8.760 < 2e-16 ***
## Age13 0.518805 0.064767 8.010 1.14e-15 ***
## Income2 -0.008529 0.018357 -0.465 0.642230
## Income3 -0.021155 0.020743 -1.020 0.307801
## Income4 -0.026865 0.023105 -1.163 0.244933
## Income5 -0.059741 0.025791 -2.316 0.020539 *
## Income6 -0.100434 0.029215 -3.438 0.000586 ***
## Income7 -0.094831 0.030359 -3.124 0.001786 **
## Income8 -0.158082 0.034751 -4.549 5.39e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## (Dispersion parameter for binomial family taken to be 1)
##
## Null deviance: 41050 on 48937 degrees of freedom
## Residual deviance: 32225 on 48894 degrees of freedom
## AIC: 32313
##
## Number of Fisher Scoring iterations: 7
#apply the best model on the test set and merge the predicted results with the true response into one data frame
predicted3 <- data.frame(obs=test$diabetes_dx,
pred=predict(poly_log, test),
predict(poly_log, test, type="prob"))
#calculate the log-loss
c <- mnLogLoss(predicted3, lev = levels(predicted3$obs))
Model selection for logistic regression
Now we have log-loss returned from 3 logistic regression models, we want to pick the one with the lowest log-loss value. In below code, we will compare their log-loss and pick the corresponding one with the lowest log-loss value.
log_pick <- data.frame(logloss_value = c(a, b, c), model = c("Logistic regression model one", "Logistic regression model two", "Logistc regression model three"))
log_best <- log_pick[which.min(log_pick$logloss_value),]
log_best
## # A tibble: 1 × 2
## logloss_value model
## <dbl> <chr>
## 1 0.329 Logistc regression model three
From the result we can tell, the Logistc regression model three has the lowest log-loss value (0.3294329), thus, the Logistc regression model three is the best logistic regression model for predicting diabetes diagnosis.
LASSO logistic regression
LASSO, standing for Least Absolute Shrinkage and Selection Operator, is a popular technique used in statistical modeling and machine learning to estimate the relationships between variables and make prediction.
The objective LASSO regression is to find the values of the coefficients that minimize the sum of the squared differences between the predicted values and the actual values, while also minimizing the L1 regularization term, which is an additional penalty term based on the absolute values of the coefficients.
Compared with basic logistic regression, LASSO logistic regression model help with the selection of variables for prediction without prior knowledge.LASSO regression model uses a penalty based method to penalize against using irrelevant predictors and also could prevent over-fitting because LASSO could reduce the “weight” for each predictor. In addition, it could be used to automate the variable selection process.
Next, we will use the caret package to fit a model to the training
set, we will assign glmnet as the model type and use log-loss to
evaluate the model performance.
lasso_log_reg<-train(diabetes_dx ~ HighBP + HighChol + CholCheck + BMI + Smoker + Stroke + HeartDiseaseorAttack
+ PhysActivity + Fruits + Veggies + HvyAlcoholConsump + AnyHealthcare + NoDocbcCost + GenHlth + MentHlth
+ PhysHlth + DiffWalk + Sex + Age + Income,
data=train,
method="glmnet",
metric="logLoss",
preProcess=c("center","scale"),
trControl=trainControl(method="cv", number = 5, classProbs=TRUE, summaryFunction=mnLogLoss),
tuneGrid = expand.grid(alpha = seq(0,1,by =0.1),
lambda = seq (0,1,by=0.1)))
head(lasso_log_reg$results)
## # A tibble: 6 × 4
## alpha lambda logLoss logLossSD
## <dbl> <dbl> <dbl> <dbl>
## 1 0 0 0.335 0.00426
## 2 0 0.1 0.346 0.00271
## 3 0 0.2 0.354 0.00207
## 4 0 0.3 0.361 0.00172
## 5 0 0.4 0.367 0.00147
## 6 0 0.5 0.371 0.00127
lasso_log_reg$bestTune
## # A tibble: 1 × 2
## alpha lambda
## <dbl> <dbl>
## 1 0.6 0
#apply the best model on the test set and merge the predicted results with the true response into one data frame
predicted6 <- data.frame(obs=test$diabetes_dx,
pred=predict(lasso_log_reg, test),
predict(lasso_log_reg, test, type="prob"))
#calculate the log-loss
f <- mnLogLoss(predicted6, lev = levels(predicted6$obs))
Classifcation tree model
classification tree is also a very straight-forward and easy to read model. By fitting a classification tree models, we can separate the predictors into different “spaces” and within each space, further split could be made based off other predictors, to generate even smaller region and so on. Classification tree model makes prediction for certain test data by taking the higher voted value from the corresponding region.
Compared with linear regression model or generalized linear model, tree methods has several advantages:
- No variable selection is needed to perform manually.
- Data preprocessing: no normalization/scaling needed.
- A classification tree model is very intuitive and generally easier to understand.
On the other hand, there are also significant drawbacks:
- A single classification tree model is inadequate for accurately predicting a response.
- Tree model takes a longer time to run compared with linear regression models.
- A small change in the data set can sometimes cause quite big changes in the classification tree structure.
So there is no perfect prediction algorithm for all problems, we need to decide based on the data set and the prediction goal. The response we are looking at is a binary factor, so fitting a classification tree model here is suitable.
class_tree<-train(diabetes_dx ~ HighBP + HighChol + CholCheck + BMI + Smoker + Stroke + HeartDiseaseorAttack
+ PhysActivity + Fruits + Veggies + HvyAlcoholConsump + AnyHealthcare + NoDocbcCost + GenHlth + MentHlth
+ PhysHlth + DiffWalk + Sex + Age + Income,
data=train,
method="rpart",
metric="logLoss",
preProcess=c("center","scale"),
trControl=trainControl(method="cv", number = 5, classProbs=TRUE, summaryFunction=mnLogLoss),
tuneGrid = data.frame(cp = seq(0,1,by = 0.1)))
class_tree
## CART
##
## 48938 samples
## 20 predictor
## 2 classes: 'No', 'Yes'
##
## Pre-processing: centered (40), scaled (40)
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 39150, 39150, 39150, 39151, 39151
## Resampling results across tuning parameters:
##
## cp logLoss
## 0.0 0.4577031
## 0.1 0.4194092
## 0.2 0.4194092
## 0.3 0.4194092
## 0.4 0.4194092
## 0.5 0.4194092
## 0.6 0.4194092
## 0.7 0.4194092
## 0.8 0.4194092
## 0.9 0.4194092
## 1.0 0.4194092
##
## logLoss was used to select the optimal model using the smallest value.
## The final value used for the model was cp = 1.
#apply the best model on the test set and merge the predicted results with the true response into one data frame
predicted7 <- data.frame(obs=test$diabetes_dx,
pred=predict(class_tree, test),
predict(class_tree, test, type="prob"))
#calculate the log-loss
g <- mnLogLoss(predicted7, lev = levels(predicted7$obs))
Random forest
The next model we will fit is a tree based model called random forest. This model is made up of multiple decision trees which are non-parametric supervised learning method and used for classification and regression. The goal of decision tree is to create a model that predicts the value of a target variable by splitting the predictor into regions with different predictions for each region. A random forest utilizes the “bootstrap” method to takes repeatedly sampling with replacement, fits multiple decision trees with a random subset of predictors, then returns the average result from all the decision trees.
Random forests are generally more accurate than individual classification trees because there is always a scope for over fitting caused by the presence of variance in classification trees, while random forests combine multiple trees and prevent over fitting. Random forests also average the predicted results from classification trees and gives a more accurate and precise prediction.
Now we can set up a random forest model for our data. we will still use
the train function but with method rf. The tuneGrid option is
where we tell the model how many predictor variables to grab per
bootstrap sample. The trainControl function within the trControl
option will be used for cross-validation with 5 folds for model
selection. After the best model is picked, use the predict function to
apply it on the test data set and merge the predicted results with the
test set’s true response. Lastly, use the mnLogLoss function to
compare their performance with a log-loss method.
ran_for <- train(diabetes_dx ~ HighBP + HighChol + CholCheck + BMI + Smoker + Stroke + HeartDiseaseorAttack
+ PhysActivity + Fruits + Veggies + HvyAlcoholConsump + AnyHealthcare + NoDocbcCost + GenHlth + MentHlth
+ PhysHlth + DiffWalk + Sex + Age + Income,
data = train,
method = "rf",
ntree = 100,
metric="logLoss",
preProcess = c("center", "scale"),
tuneGrid = data.frame(mtry = c(5:15)),
trControl = trainControl(method = "cv", number = 5, classProbs=TRUE, summaryFunction=mnLogLoss))
ran_for
## Random Forest
##
## 48938 samples
## 20 predictor
## 2 classes: 'No', 'Yes'
##
## Pre-processing: centered (40), scaled (40)
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 39150, 39150, 39151, 39151, 39150
## Resampling results across tuning parameters:
##
## mtry logLoss
## 5 0.4944615
## 6 0.4778212
## 7 0.4648374
## 8 0.4481790
## 9 0.4599590
## 10 0.4485821
## 11 0.4604299
## 12 0.4657279
## 13 0.4717324
## 14 0.4719124
## 15 0.4796055
##
## logLoss was used to select the optimal model using the smallest value.
## The final value used for the model was mtry = 8.
#apply the best model on the test set and merge the predicted results with the true response into one data frame
predicted4 <- data.frame(obs=test$diabetes_dx,
pred=predict(ran_for, test),
predict(ran_for, test, type="prob"))
#calculate the log-loss
d <- mnLogLoss(predicted4, lev = levels(predicted4$obs))
Logistic model tree
There is one classification model called logistic model tree, it combines logistic regression and decision tree – instead of having constants at leaves for prediction as the ordinary decision trees, a logistic model tree has logistic regression models at its leaves to provide prediction locally. The initial tree is built by creating a standard classification tree, and afterwards building a logistic regression model at every node trained on the set of examples at that node. Then, we further split a node and want to build the logistic regression function at one of the child nodes. Since we have already fit a logistic regression at the parent node, it is reasonable to use it as a basis for fitting the logistic regression at the child. We expect that the parameters of the model at the parent node already encode ‘global’ influences of some attributes on the class variable; at the child node, the model can be further refined by taking into account influences of attributes that are only valid locally, i.e. within the set of training examples associated with the child node.
The logistic model tree is fitted by the LogitBoost algorithm which iteratively changes the logistic regression at chile node to improve the fit to the data by changing one of the coefficients in the linear function or introducing a new variable/coefficient pair. At some point, adding more variables does not increase the accuracy of the model, but splitting the instance space and refining the logistic models locally in the two subdivisions created by the split might give a better model. After splitting a node we can continue running LogitBoost iterations for fitting the logsitc regression model to the response variables of the training examples at the child node.
Thus, we tune logistic model tree by giving iteration number. For our
training set, we use the LMT method in train function and set the
iteration number to 1 to 3.
log_tr <- train(diabetes_dx ~ HighBP + HighChol + CholCheck + BMI + Smoker + Stroke + HeartDiseaseorAttack
+ PhysActivity + Fruits + Veggies + HvyAlcoholConsump + AnyHealthcare + NoDocbcCost + GenHlth + MentHlth
+ PhysHlth + DiffWalk + Sex + Age + Income,
data = train,
method = "LMT",
metric="logLoss",
preProcess = c("center", "scale"),
tuneGrid = data.frame(iter = c(1:3)),
trControl = trainControl(method = "cv", number = 5, classProbs=TRUE, summaryFunction=mnLogLoss))
log_tr
## Logistic Model Trees
##
## 48938 samples
## 20 predictor
## 2 classes: 'No', 'Yes'
##
## Pre-processing: centered (40), scaled (40)
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 39151, 39150, 39150, 39151, 39150
## Resampling results across tuning parameters:
##
## iter logLoss
## 1 0.3597232
## 2 0.3493104
## 3 0.3454356
##
## logLoss was used to select the optimal model using the smallest value.
## The final value used for the model was iter = 3.
#apply the best model on the test set and merge the predicted results with the true response into one data frame
predicted5 <- data.frame(obs=test$diabetes_dx,
pred=predict(log_tr, test),
predict(log_tr, test, type="prob"))
#calculate the log-loss
e <- mnLogLoss(predicted5, lev = levels(predicted5$obs))
Linear discriminant analysis
This is also another linear model available in the caret package
called Linear discriminant analysis (discriminant correspondence
analysis), it is a method for finding a linear combination of features
that characterizes or separates two or more classes of response. LDA is
very similar to logistic regression as it explains a categorical
variable by the values of continuous independent variables.It is also
closely related to principal component analysis which looks for linear
combinations of variables that best explain data. One difference is that
LDA explicitly attempts to model the difference between the classes of
data.
Since our response is binary data, We will use lda as model type to
fit a Linear discriminant analysis model as below:
class_CART<-train(diabetes_dx ~ HighBP + HighChol + CholCheck + BMI + Smoker + Stroke + HeartDiseaseorAttack
+ PhysActivity + Fruits + Veggies + HvyAlcoholConsump + AnyHealthcare + NoDocbcCost + GenHlth + MentHlth
+ PhysHlth + DiffWalk + Sex + Age + Income,
data=train,
method="lda",
metric="logLoss",
preProcess=c("center","scale"),
trControl=trainControl(method="cv", number = 5, classProbs=TRUE, summaryFunction=mnLogLoss))
class_CART
## Linear Discriminant Analysis
##
## 48938 samples
## 20 predictor
## 2 classes: 'No', 'Yes'
##
## Pre-processing: centered (40), scaled (40)
## Resampling: Cross-Validated (5 fold)
## Summary of sample sizes: 39150, 39151, 39150, 39150, 39151
## Resampling results:
##
## logLoss
## 0.3400984
#apply the best model on the test set and merge the predicted results with the true response into one data frame
predicted8 <- data.frame(obs=test$diabetes_dx,
pred=predict(class_CART, test),
predict(class_CART, test, type="prob"))
#calculate the log-loss
h <- mnLogLoss(predicted8, lev = levels(predicted8$obs))
Final model selection
Now, best models are chosen for each model type, we are going to compare
all six models log-loss values from running on the test set then pick
the final winner. Just like previous step, we will create a data frame
with all six log-loss values and their corresponding model names, then
return the row with the lowest log-loss value by using the which.min
function. Finally, we will insert the model name as an inline R code
into the conclusion.
final_pick <- data.frame(logloss_value = c(f, g, d, e, h), model = c("LASSO logistic regression model", "Classification tree model", "Random forest model", "Logistic model tree", "Linear discriminant analysis model"))
#append with previous best logistic model
final_pick <- rbind(final_pick, log_best)
final_pick
## # A tibble: 6 × 2
## logloss_value model
## <dbl> <chr>
## 1 0.333 LASSO logistic regression model
## 2 0.419 Classification tree model
## 3 0.459 Random forest model
## 4 0.344 Logistic model tree
## 5 0.340 Linear discriminant analysis model
## 6 0.329 Logistc regression model three
#return the smallest log-loss model
final_best <- final_pick[which.min(final_pick$logloss_value),]
final_best
## # A tibble: 1 × 2
## logloss_value model
## <dbl> <chr>
## 1 0.329 Logistc regression model three
Finally, after comparing all six models’ log-loss values fitting on the test set, the Logistc regression model three has the lowest log-loss value (0.3294329), thus, the Logistc regression model three is the best model for predicting diabetes diagnosis.